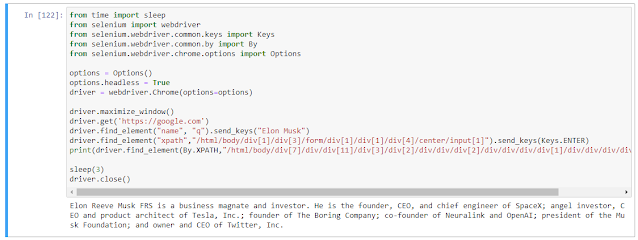
This is a very simple example. But you will know the dynamics to alter for achieving the right results.
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
options = Options()
options.headless = True
driver = webdriver.Chrome(options=options)
driver.maximize_window()
driver.get('https://www.w3schools.com/html/html_tables.asp')
# Make Python sleep for some time
sleep(2)
rows = len(driver.find_elements("xpath","/html/body/div[7]/div[1]/div[1]/div[3]/div/table/tbody/tr"))
# Obtain the number of columns in table
cols = len(driver.find_elements("xpath","/html/body/div[7]/div[1]/div[1]/div[3]/div/table/tbody/tr/td"))
# Printing the data of the table
for r in range(2, rows+1):
for p in range(1,4):
#obtaining the text from each column of the table
value = driver.find_element("xpath","/html/body/div[7]/div[1]/div[1]/div[3]/div/table/tbody/tr["+str(r)+"]/td["+str(p)+"]").text
print(value)